

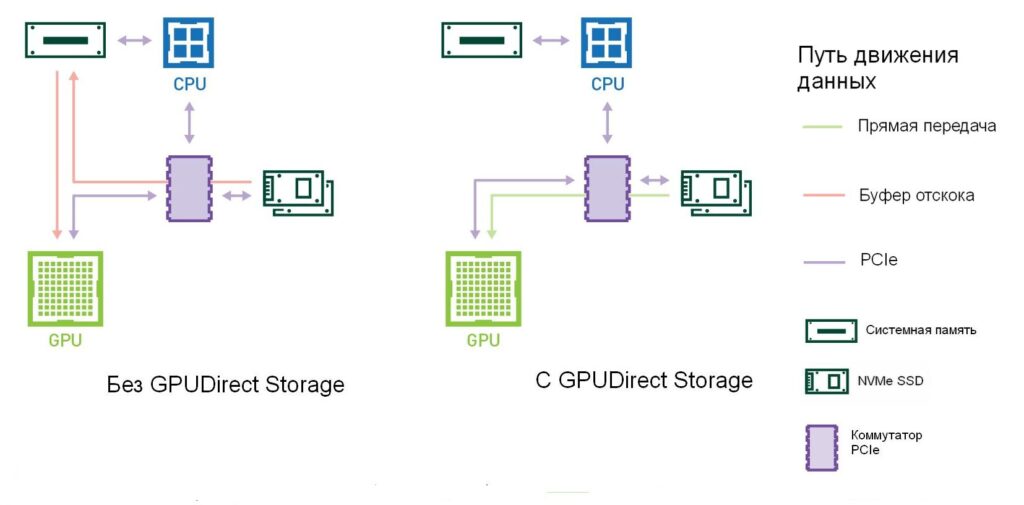
GPUDirect Storage обеспечивает прямой путь между хранилищем и памятью графического процессора минуя центральный процесор.
Источник: https://developer.nvidia.com/blog/gpudirect-storage/
Блог рассказывает о технологии GPUDirect. В качестве примера взята платформа NVIDIA DGX-2 с 16 ускорителями Tesla V100.
Обеспечение загрузки GPU
Наборы данных AI и HPC продолжают увеличиваться в размерах. Ввод-вывод, процесс загрузки данных из хранилища в графические процессоры для обработки, исторически контролировался центральным процессором. По мере того, как вычисления переключаются на более быстрые графические процессоры, ввод-вывод становится все более узким местом для общей производительности приложения.
GPUDirect RDMA (Remote Direct Memory Address) улучшает пропускную способность и задержки при перемещении данных напрямую между сетевой картой (NIC) и памятью графического процессора.
Новая технология, называемая GPUDirect Storage, обеспечивает прямой путь данных между локальным или удаленным хранилищем, например NVMe или NVMe over Fabric ( NVMe-oF) и памятью графического процессора. И GPUDirect RDMA, и GPUDirect Storage избегают дополнительных копий через буфер отскока (bounce buffer) в системной памяти ЦП. Обе технологии используют механизм прямого доступа к памяти (DMA) для перемещения данных по прямому пути, минуя CPU или GPU (Рисунок 1).
Для GPUDirect Storage местоположение хранилища не имеет значения; он может находиться локально внутри сервера или в пределах стойки или подключаться по сети. Пропускная способность от системной памяти ЦП (SysMem) к графическим процессорам в NVIDIA DGX-2 ограничена 50 ГБ / с. Благодаря GPUDirect Storage, совокупную пропускную способность системной памяти, ряда локальных дисков и сетевых адаптеров можно объединить в DGX-2 для достижения верхнего предела почти до 200 ГБ / с.

Принципиальную возможность реализации технологии и предварительные замеры производительности были продемонстрированы на GTC19 в Сан-Хосе. По мере готовности продукта к статусу «в производстве» набор API cuFile будет добавлен в CUDA для поддержки этой функции вместе с собственной интеграцией в библиотеку cuDF RAPIDS.
Как работает прямой доступ к памяти
Интерфейс PCI Express (PCIe) соединяет высокоскоростные периферийные устройства, такие как сетевые карты, хранилище RAID / NVMe и графические процессоры, с центральными процессорами. Интерфейс PCIe Gen3 для графических процессоров Volta, обеспечивает теоретическую совокупную пропускную способность 16 ГБ / с. После оптимизации протокола по снижению накладных расходов, максимально достижимая скорость передачи данных превышает 14 ГБ / с.
Прямой доступ к памяти (DMA) использует механизм копирования для асинхронного перемещения больших блоков данных через PCIe, но не не для загрузки и сохранения. Он разгружает центральные процессоры, оставляя их свободными для другой работы. В графических процессорах и устройствах, связанных с хранилищами, таких как накопители NVMe и контроллеры хранилища, есть механизмы DMA, но, как правило, они не поддерживаются центральным процессором.
В некоторых случаях механизм прямого доступа к памяти не может быть запрограммирован для необходимого пункта назначения. Например, механизмы DMA GPU не могут работать с хранилищем. Механизмы DMA хранилища не могут напрямую обращаться к памяти графического процессора минуя файловую систему. Это ограничение обходится с помощью GPUDirect Storage.
Механизмы DMA должны быть запрограммированы драйвером центрального процессора для конкретного устройства. Выбор устройства с DMA имеет значение. Когда центральный процессор обращается к DMA графического процессора (ГП), команды от него к ГП могут мешать другим командам ГП. Если же механизм DMA для перемещения данных может быть включен для накопителя NVMe или контроллера хранилища вместо DMA графического процессора, то на пути между процессором и графическим процессором не возникает дополнительных помех.
Использование механизмов DMA на локальных накопителях NVMe по сравнению с механизмами DMA графического процессора увеличило пропускную способность ввода-вывода до 13,3 ГБ / с. Это дало увеличение производительности примерно на 10% по сравнению со скоростью передачи памяти процессора в память графического процессора 12,0 ГБ / с. Цифры приводятся в таблице ниже.
Описание платформы-прототипа

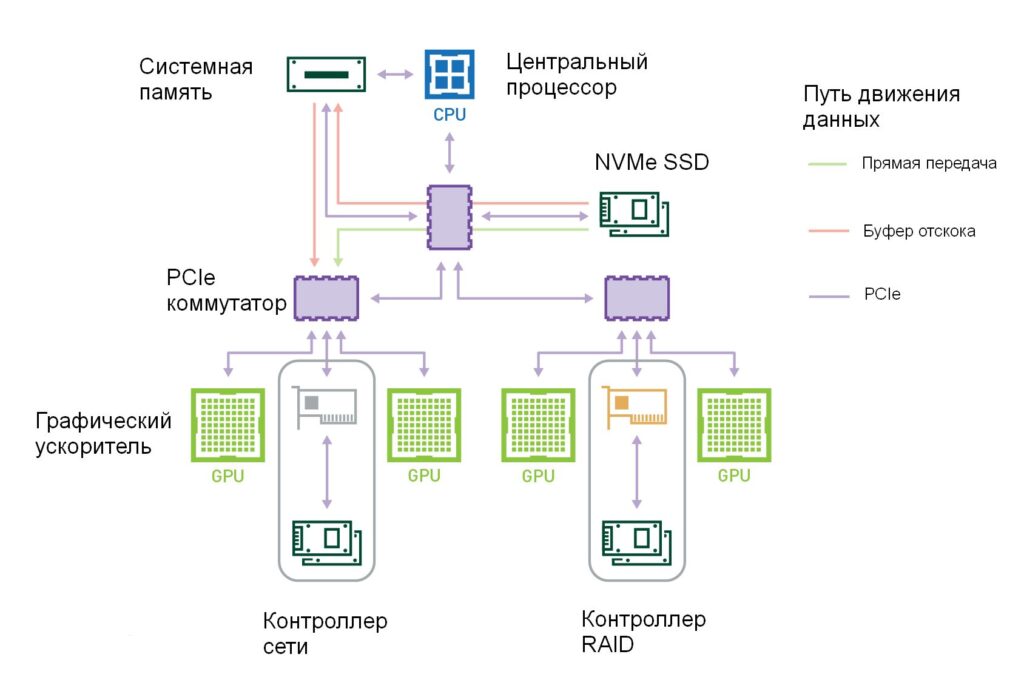
Платформа DGX-2 содержит два ЦП, и каждый ЦП имеет два экземпляра поддерева PCIe, показанных на рисунке 2. Множественные пути PCIe от хранилища или системной памяти, поддерживаемые двумя уровнями коммутаторов PCIe в графические процессоры, делают DGX-2 хорошим тестовым средством. для прототипирования GPUDirect Storage. В левом столбце таблицы 1 перечислены различные источники передачи данных в графический процессор, во втором столбце указана измеренная пропускная способность от этого источника, в третьем столбце указано количество таких путей, а в последнем столбце указано произведение двух средних столбцов, показывающих общую пропускную способность, доступную от такого источника.
Существует один путь из системной памяти ЦП (SysMem) для каждого из 4-х деревьев PCIe со скоростью 12–12,5 ГБ / с и еще один путь от дисков, которые подключены к каждому дереву PCIe со скоростью 13,3 ГБ / с. DGX-2 имеют один слот PCIe на пару графических процессоров.Этот слот может быть занят либо сетевой картой, которая показывает скорость 10,5 ГБ / с, либо, в случае нашего прототипа, использованного для этого блога, картой RAID, которая показывает скорость 14 ГБ / с. NVMe-oF (через фабрику) — это распространенный протокол, который использует сетевую карту для доступа к удаленному хранилищу, например, по сети Infiniband. Правый столбец пропускной способности PCIe, добавленной по всем источникам, можно суммировать до 215 ГБ / с, если карты RAID используются в 8 слотах PCIe (по 2 на поддерево PCIe на рисунке 2); сумма была бы меньше, если бы вместо этого в этих слотах использовались сетевые адаптеры.Правый столбец пропускной способности PCIe, добавленной по всем источникам, можно суммировать до 215 ГБ / с, если карты RAID используются в 8 слотах PCIe (по 2 на поддерево PCIe на рисунке 2); сумма была бы меньше, если бы вместо этого в этих слотах использовались сетевые адаптеры.Правый столбец пропускной способности PCIe, добавленной по всем источникам, можно суммировать до 215 ГБ / с, если карты RAID используются в 8 слотах PCIe (по 2 на поддерево PCIe на рисунке 2). Сумма была бы меньше, если бы вместо этого в этих слотах использовались сетевые адаптеры.
| Источник данных для GPU | Пропускная способность на одно дерево PCIe, ГБ / с | Количество путей PCIe в DGX-2 | Общая пропускная способность на DGX-2, ГБ / с на направление |
| От системнаой памяти | 12.0-12.5 | 4 | 48.0-50.0 |
| От внутреннего NVMe SSD | 13.3 | 4 | 53.3 |
| От внешнего источника через NIC | 10.5 | 8 | 84.0 |
| От RAID контроллера | 14.0 | 8 | 112.0 |
| Максимальный поток Память + NVMe SSD + RAID | 215 | ||
| GPU | > 14.4 | 16 | > 230 |
Результаты
Ключевая функциональность, предоставляемая GPUDirect Storage в том, что она формирует DMA доступ из хранилища непосредственно в память GPU. Тесты GPUDirect Storage показали следующие его преимущества :
- Пропускная способность в 2-8 раз выше благодаря передаче данных напрямую между хранилищем и графическим процессором.
- Явная передача данных, которая не вызывает сбоев и не проходит через буфер отскока, также снижает задержку; есть примеры с уменьшенной в 3,8 раза сквозной задержкой.
- Предотвращение сбоев с помощью явной и прямой передачи позволяет задержке оставаться стабильной и постоянной по мере увеличения параллелизма GPU.
- Использование механизмов DMA в привязке к хранилищу обладает наименьшим влиянием на загрузку ЦП и не влияет на загрузку ГП.
- Тестирование показало (авторы не показали это на графиках в блоге), что влияние на графический процессор остается близким к нулю, когда сторонние механизмы DMA загружают или извлекают данные в память графического процессора.
Графический процессор становится не только вычислительным механизмом с самой высокой пропускной способностью, но и вычислительным элементом с самой высокой пропускной способностью ввода-вывода, например 215 ГБ / с против 50 ГБ / с процессора.
Все эти преимущества достижимы независимо от того, где хранятся данные — обеспечивается очень быстрый доступ к петабайтам удаленного хранилища, даже быстрее, чем кеш страниц в памяти ЦП.
Полосы пропускания к памяти графического процессора от системной памяти процессора, локального хранилища и удаленного хранилища могут быть объединены, чтобы соответствовать пропускной способности графических процессоров.
